

Distributed == Relational
Perhaps surprisingly, distributed systems are naturally relational

The style of distributed architecture described here is at the heart of the design of FREST.
The basic story
Assume we have four systems. System A wants to invoke a function on system D, but the function in D needs arguments from systems B and C.

The typical pragmatic solution is for A to sequentially request the information from B and C, and then send all the arguments to D.
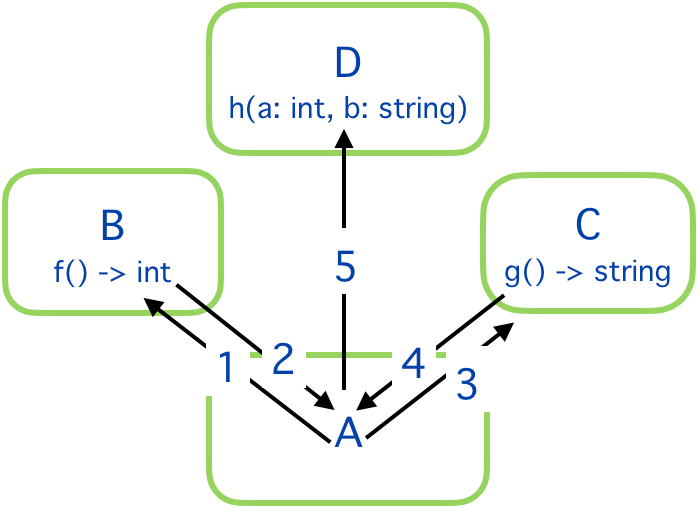
This is not taking maximum advantage of parallelism, but is simple to write and good enough for most purposes. Notice that invoking h takes 5 sequential operations.
A maximally efficient solution would have A send messages to B and C, which would in turn send their results to D.

Now we have two parallel sequential operations. A isn’t waiting around with some suspended process taking up resources; it is done. The effort required from B and C is the same as in the sequential solution, but they can execute simultaneously.
Using current paradigms, manually writing the logic for every endpoint to participate in every such exchange is prohibitively complex. B and C might be written by different teams!
What if I tell you there is a simple existing technology that makes the maximally distributed solution natural to write?
The message A → B has to be able to specify where B should send its result. The same with A → C. It’s easy enough for A to include a destination URL in its messages for this purpose.
It’s inside D where things get interesting. Its function h is being invoked not in one go, but sort of gradually. It will receive messages from B and C, in any order, and when both messages have been received, then h can execute.
So D has to be able to cache the arguments to function calls. This means that B and C need some way to indicate that the message they’re sending are for the same function invocation. So there will have to be an identifier for the function invocation.
As an example, we might submit the arguments to a function as query parameters in a URL. Perhaps /h/<id>?a=<arg1>. A will have generated a UUID that it sent to both B and C in the destination argument for their results.
Assume for simplicity that functions take a fixed number of required arguments.
Notice that invoking a function now involves storing any of a fixed set of key-value pairs to a location specified by a (function) name and id. The location specified by the id should be created if it doesn’t exist; otherwise its values are updated.
But this is logically identical to performing an upsert operation on a table!
Seen this way, the function invocation is naturally expressed as a trigger on a table that first checks following an update whether the row has no null columns, and if so, executes the function, passing the row values as arguments.
Relations + Functions + Continuations
A distributed computing system, then, is naturally expressed as a set of relational stores with triggers.
Note that the receiving function for the results might be another trigger table, but can be any sort of HTTP endpoint1, even on an entirely different service.
This design is what Functional Programming has long called continuation-passing style. Many languages have recently adopted the await keyword as a way of synchronising asynchronous systems. What await is silently doing in such languages is turning the rest of the function after the await into a continuation function. Continuation Passing Style is entirely mainstream at this point.
Don’t worry about SQL
It is worthwhile to address in passing a concern that many folks will have at this point: SQL is awful, and writing triggers is a pain in the ass. This is absolutely true but not terribly important.
First: any SQL platform worth using (this means, basically, not MySQL2) supports writing triggers in Python, which no-one considers a terrible language.
Second: PostgreSQL is the best database for programming by such a wide margin, it’s astonishing. PostgreSQL supports triggers in any of 16 programming languages.
Third, PostgresSQL, SQL Server and SQLite (using host language custom functions) can notify external/host programs of data changes (using LISTEN/NOTIFY in Postgres, Query Notifications in SQL Server, Change Notifications in Oracle and triggers with custom functions in SQLite).
It is thus possible with a lightweight framework to effectively support trigger functions written in a straightforward way in a nice programming language.
Also, the world might (finally!), just a little, be waking up to just how awful SQL is, and we see projects such as the wonderful SurrealDB to provide relational databases not based on SQL.
Querying
Since we have to have a relational store, it will be natural to support relational querying. SQL is abominable, so we’ll have something better, probably Datalog or some moral equivalent.
Functions, you say?
I’ll elaborate more on this in later posts, but to provide a taste of what’s to come, I’ll briefly discuss some of the interesting consequences of this model of function invocation.
First, note that we’re allowing API clients to create endpoints for their own purposes. There is nothing, for example, to prevent a single function invocation being triggered by data coming from multiple different organisations (modulo a good security story, which we have but this will have to be discussed later).
Since we’re doing function calling, a natural thing would be for our servers to support functional programming operations, such as map and fold. Allowing API clients to do filtering and such things server side will let them make custom API endpoints that reduce load for both them and the service provider. No need to have clumsy endpoints that provide everything and the kitchen sink that the API clients might not need.
We will allow a function invocation to be partially completed and then locked, meaning it can’t be fully completed. Rather, a message can be sent to the address of the locked row, but must include a different id as an argument. The values from the locked row can then be copied to the new id, along with any other arguments supplied. In this way, we can allow API clients to employ partial functions they can define, and combined with the likes of map and fold, customise our service in a way that is both simple and flexible.
This is programming, but without using a programming language. We could implement a LISP or something to make this easier, but we’re not letting API clients just run their own code on our servers3.
Because SQL has so poisoned the well, relations have been grossly underutilised in programming. The model for programming we’re developing here will inevitably lead to expressing much more of business logic in a relational manner, producing software that is simpler, more correct, and more malleable than software that expresses business logic in a regular programming language. More on this soon.
Finally, some very interesting possibilities arise out of supporting a reactive UI on top of such a system. Since we’re using a database, we can automatically generate a user interface much as Access or FileMaker do. Programmers will be freed from such quotidian tedium as hand-rolling yet another HTML form. More on this, soon, also.
Conclusion
Truly efficient distributed systems are most naturally expressed through functions as triggers invoked from upsert operations on addressable relations.
Having adopted this paradigm, interesting possibilities arise out of adding functional programming operations and reactive user interfaces.
These considerations form the heart of the design of FREST.
We shall not require HTTP; it will eventually be possible to run FREST over SOAP or gRPC or whatever; HTTP is suitable for exposition, however.
MySQL is actually strictly less capable than SQL Server, PostgreSQL and Oracle, and given its intended uses, even SQLite. It is beyond me why anyone sane would choose to use it.
Hi Guyren
Interesting writeup. We have a programming model that covers much of what you describe:
https://gitlab.com/masr/bspl/-/tree/kiko/
This article describes a diamond-topology example that is similar to yours, but more complex in that some of the messages have composite identifiers.
https://www.lancaster.ac.uk/staff/chopraak/pdfs/PoT.pdf
Best
Amit Chopra
You hit the point.. i was searching with similar idea . Please check out quine.io and specifically standing queries (triggers) .